Hortonworks 介紹
內容目錄
Hortonworks 資料平台內含:
Apache Atlas 資料控管架構
Hadoop 社群中最受歡迎的資料控管架構
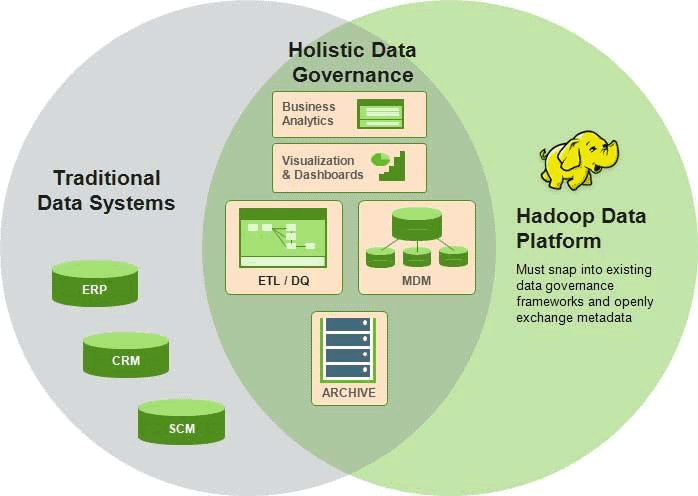
隨著企業體佈署 Hadoop 架構來整合內部各部門龐大的資料,就一定得面對後設資料(Metadata)管理與資料控管問題。Apache Atlas 便是由各大企業與 Hortonworks 攜手打造的資料控管架構。
Atlas 採用分類法形式的後設資料(Taxonomical Metadata)建立時效性分析模型(Prescriptive Models)與鑑識型分析模型(Forensic Models)來強化 Hadoop 上資料控管能力;針對在 Hadoop Stack 上處理與交換後設資料的設計,使 Atlas 能夠在不同平台上進行控管,以迎合企業應用上需求。
Apache Spark
Spark 技術為 Hadoop 平台帶來了記憶體內 ETL 處理能力、機器學習以及資料科學技術
Apache Spark 有什麼功能?
Apache Spark 是高速記憶體內資料處理引擎,其簡潔又豐富的 API 允許資料分析師對需要快速反覆存取資料進行有效率的串流處理、機器學習以及 SQL 運算。將 Spark 佈署在 Apache Hadoop YARN 架構之上,在任何地方的開發者都能充分使用 Spark 的功能,在 Hadoop 上共用的資料叢集進行精闢的資料處理與分析。
Spark 搭配 HDP,便能成為 YARN 框架下的資料查詢引擎:使的 Spark 與其他應用程式能在 Hadoop 的 YARN 框架下共用同一個資料叢集,同時又確保穩定一致的服務與回應。
Apache Spark 包括了Spark 核心引擎以及函式庫兩部份:Spark 核心是分散式運算引擎,並且為分散式 ETL 提供了Java、Scala 與 Python API 的開發平台。
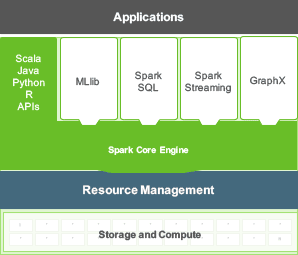
基於核心引擎的各式函式庫能提供串流處理、SQL 查詢或機器學習等各類行的工作任務。
Spark 的抽象化設計,讓資料分析變得更順手:資料科學家常常使用機器學習工具從資料取得新資訊,而這些演算法多半是迭代式的運算,而 Spark 將資料快取在記憶體內的技術便能夠大幅加快這類的資料迭代運算,使的 Spark 成為開發資料分析演算法的資料處理引擎首選。
Spark 內包含 MLlib 函式庫:MLlib 內提供了許多資料分析常用技術的函式庫支援,舉凡分類演算法(Classification Algorithms)、回歸分析(Regression Analysis)、協同過濾(Collaborative Filtering)、群集分析(Clustering Analysis)以及降維分析(Dimensionality Reduction)等等都有提供支援。
Spark 的 ML Pipeline API 則是將資料分析高度抽象化的工具:利用 ML Pipeline 能夠快速建立機器學習演算法流程,並提供 Transformer, Estimator, Pipeline 與 Parameters 等抽象化 API。這層抽象化的設計讓資料科學家能更快速取得成果。