Greenplum Database 是什麼? 基本觀念、架構以及適用場景介紹
內容目錄
Greenplum 是什麼?
Greenplum 是一種建立在 PostgreSQL 基礎上的大規模平行(MPP)資料倉儲。Greenplum 能夠輕易地針對 PB 級資料,提供高效、快速的分析,使用者只需透過 SQL 語法,就能控制和查看伺服器叢集上的資料。另外,Greenplum 是混合 OLTP + OLAP 的 HTAP 架構,因此能執行複雜的資料查詢,也同時適合作為 BI 系統以及報表工具。
這篇文章,我們將詳細介紹 Greenplum 的基本觀念、優勢以及適用場景。
學習資源:如果想瞭解關於 Greenplum 與 PostgreSQL 之間的關係,可以閱讀我們另一篇文章 Greenplum 和 PostgreSQL 的關係為何?
MPP 架構是什麼?
在介紹 MPP 架構前,我們需要先知道它被用來解決什麼樣的問題。
過往在處理資料時,人們必須依賴單機台的對稱性多核處理器。然而隨著資料量成長,這些單機台的硬體資源逐漸無法應付與日俱增的資料量,就會出現所謂的「效能瓶頸」。
為了解決這個問題,就必須持續升級硬體資源,例如:升級 CPU、加掛更多硬碟或加大記憶體,我們稱這種做法為「垂直擴展」。然而,垂直擴展容易導致龐大的開銷和硬體耗損過快;此外,單機架構在資料發生損毀時,使用者並沒有相應的備援措施。
圖片來源:Scalability in Cloud Computing: Horizontal vs. Vertical Scaling
MPP 架構就是來解決垂直擴展所面臨的挑戰,MPP 架構採用「水平擴展」的解決方案來擴充硬體資源。
原理是先將資料平均備份到系統所有的節點伺服器上,使所有節點儲存全部資料的一部分,主節點接受查詢請求後,會產生最佳執行計劃,使運算節點可各自在無共享資源 (Share Nothing) 情況下,快速完成被分發到的部分作業,並回報給主節點,實現高速的計算效能。
因此使用 MPP 架構的 Greenplum ,除了擁有水平擴展的彈性因應龐大的資料儲存需求,更可以實現快速運算,使 Greenplum 成為分析型資料倉儲。

圖片來源:Scalability in Cloud Computing: Horizontal vs. Vertical Scaling
Greenplum 架構:
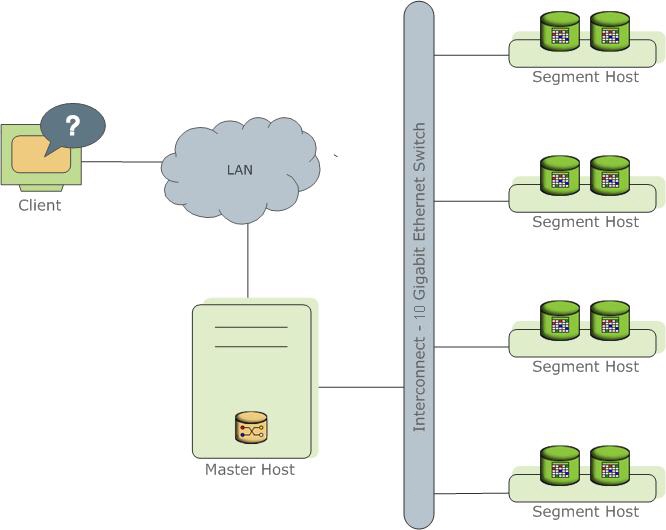
Greenplum 是由 Master、Segment 和 Interconnect 等重要元素組成,本段將為各位詳細介紹它們的用處以及在 Greenplum 架構中扮演的腳色。
Greenplum Master:
Master 節點是訪問整個系統的入口,它負責處理使用者連線資料庫、產生 SQL 執行計畫和將工作分配給不同節點。
Master 也是全局系統目錄的位置。全局系統目錄表是一組包含 Greenplum 設定檔資料的系統表。當 Master 在處理 SQL 指令時,它會將這些工作分配到其他的 Segment node 來執行,並返回請求的資料內容或將結果寫入到資料庫中。
Greenplum Segment:
Greenplum 的 Segment 是由多台單機版的 PostgreSQL 實例(Instance)組成,它們負責儲存資料並執行主節點分發的查詢計畫。
Segment 運行在一個名為 Segment Host 的伺服器上。一個 Segment Host 通常能夠運行 2 至 8 個 Segment,Segment Host 能夠運行 Segment 的數量取決於伺服器 CPU 核心、RAM、容量以及作業負載,因此建議用相同的方式設定 Segment Host 。
發揮 Greenplum 最大效能的關鍵在於配置性能相近的 Segment , 並將工作負載平均地分配至每個 Segment 中,這樣查詢才能同時開始,同時結束。
Greenplum Interconnect:
Interconnect 是 Greenplum 架構中,節點用來相互傳遞訊息的網路。Greenplum Interconnect 使用以太光纖網路,為了提高效能,建議使用 10 GbE 以上的網速。
在 Greenplum 的預設中,Interconnect 使用具備流量控制的用戶資料通協定(User Datagram Protocol)讓節點之間相互交流。由於 Greenplum 利用 UDP 執行封包測試,它的性能相較於 TCP 又更勝一籌。但是如果將 UDP 換成 TCP ,Greenplum 的可擴展性將會被限制在 1,000 個節點上,如果改回 UDPIFC,Greenplum 水平擴展的節點數就沒有限制。
Greenplum 的適用場景
機器學習(ML)
Greenplum 非常適合機器學習,因為它支援一種名為 Apache MADlib 的開源技術。Apache MADlib 是基於 SQL 的機器學習資源庫,能夠同時在 Greenplum 和 PostgreSQL 上運行。
使用 MADlib 能夠幫助強化部署 Greenplum 機器學習時的並行性、可過展性和預測的精準性。MADlib 還提供用於機器學習的資料轉換和特徵工程(feature engineering),例如:描述型統計和推論統計、樞紐分析和 標籤行變數的編碼。
舉例來說,政府的防詐部門透過將 Greenplum 與 GemFire 結合,建立大規模的詐騙偵測系統,來預防個資外洩,每年還能節省 50 億美元的開銷。
進階資料分析(Advanced Analytics)
Greenplum 的進階資料分析功能被廣泛應用於不同產業,Greenplum 的優勢在於,能夠分析多樣的資料型態、讓使用者利用 SQL 語法執行指令並利用 MPP 架構的優勢訓練分析模型。
另外,Greenplum 提供本地資料庫分析(in-database analytics),使用者能夠直接在資料庫內進行分析,無需介接外部資料表。除此之外,你還能在 Greenplum 中使用多樣化的分析工具,例如:Apache MADlid、R 語言、SAS 和 PMML。
舉例來說,一間網路電商利用 Greenplum 的進階分析功能進行受眾分析,幫助這些企業更了解客戶的喜好、使用的裝置以及地理位置。
AI (人工智慧)
人工智能雖然在概念上與機器學習(ML)相似,但相比於機器學習,它又更加廣義,即機器在透過學習後,能夠更聰明地執行任務。任何希望利用智能機器模仿人類行為的使用者,Greenplum 會是一個非常好的選擇。
受益於 Greenplum 儲存巨量資料的優勢,它能為智能應用程式帶來巨大的效益,因為這些應用程式需要數量大量的應用場景來訓練 AI 模型。
Greenplum 的優勢為何?
(一) 高效能
Greenplum 特殊設計的資料流(Data Pipeline),讓資料不用符合 RAM 的大小,也能高效地從磁碟傳送至 CPU 。Greenplum 水平擴充的特性消弭大多關聯式資料庫(RDBMS)擴展至 PB 級資料量時面臨的挑戰。
詳細資訊可以參考 Greenplum Next Generation Big Data Platform: Top 5 Reason。
(二)資料庫查詢優化(Query Optimization)
Greenplum 的成本導向優化查詢器(cost-based query optimizer)、視覺化和批次報表產出功能能在不降低查詢效率的情況下,高效處理巨量資料。 由於 Greenplum 採用 MPP Scatter/Gather Streaming 技術。因此在 Greenplum 的架構中,每加入一個節點,載入速度都會提高,最高可達每小時 10 TB 。
另外,隨著 Greenplum 6 版 OLTP(線上交易處理)功能的更新,單一查詢效能相較 Greenplum 5 版有顯著的提升, 在 6 版中,Greenplum 解決了資料表發生死鎖(Dead Lock)的問題,使得主節點 CPU 的使用率得以超過 90%。Greenplum 6 版透過提高主節點的使用率,提升資料庫的查詢效率。
(三) 多樣化的資料儲存模型(Polymorphic Data Storage)
Greenplum 多樣化的資料儲存模型提供使用者豐富的儲存配置選擇,使用者能夠依需求進行資料表壓縮,讓他們能夠依照特殊的資料存取方式設計資料表,並擁有欄與列的資料儲存結構。
在使用 Greenplum 建立資料表時,你能夠選擇將資料以欄或列的結構儲存。欄的儲存結構(Column oriented )適合全表掃描(Full Scan),而列的儲存結構則適合條件式查詢。
(四) 與 PostgreSQL 的高度兼容性
終端使用者在使用 Greenplum 時,不會發覺它與 PostgreSQL 的差異。因為 Greenplum 支援與 PostgreSQL 相同的驅動程式,例如:JDBC、ODBC 或 libpq。
Greenplum 的常見功能
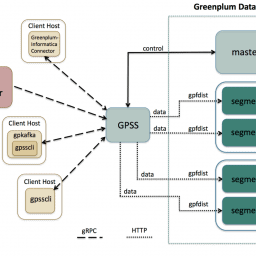
Greenplum pgfdist
GPFDIST 是 Greenplum Database parallel file distribution program 的縮寫,專門用於處理 Greenplum 對外部檔案進行讀取或寫入。由於 GreenPlum 將自身定位為可處理 PB 等級資料的數據倉儲產品,因此在實際應用場景中,必然會有 ETL 大量資料匯入的需求,此時就可以透過 GPFDIST 以平行處理、協同作業的方式進行極為快速的資料處理。
一般來說,要將外部資料匯入資料庫的方法主要有下面兩種:
(1) 單純一筆一筆資料匯入
(2) COPY from File
而上述方法都需要仰賴 Master (主節點) 耗費資源來獨立處理,因此可以想像當有大量資料待處理時,不但耗時甚久更可能影響到其他作業程序。
為了解決上述問題並且加速匯入流程,Greenplum 提供了一個基於其 MPP 架構 (Massively Parallel Processor) 的內部套件,也就是 GPFDIST。
透過 GPFDIST 可以驅動各個 SEGMENT 平行讀寫來源檔案,進而增加匯入效率。
學習資源:想了解更多 Greenplum pgfdist 資訊,請參考我們的文章:PB 級 ETL 獨門秘器 – Greenplum GPFDIST 介紹與使用情境
支援 XML 資料類型
Greenplum 能夠檢查匯入資料庫的 XML 資料是否完整,為 XML 資料存入資料庫提供便利性。
詳細資訊請參考:Working with XML Data