大數據分析查詢引擎大車拼!Hadoop Hive VS. Impala 是競爭還是相輔相成?
是競爭還是相輔相成?
Impala 與 Hive 都是構建在 Hadoop 之上的資料查詢工具,但許多人卻不清楚它們各自的特色與使用情境。其實,從它們的名字就可以略知一二,Hive 是大資料倉儲工具,像蜂巢一樣貯藏了很多蜂蜜,但卻無法快速拿出來;Impala 可以讀寫 Hive 資料,速度和羚羊一樣飛快…
既然 Impala 效能更好,也可以讀寫 Hive 資料,所以可以直接取代 Hive 嗎?
事情當然沒這麼簡單,本篇文章將從 Hive 與 Impala 的基本架構開始,說明它們各自的長處與限制。
Hive VS. Impala 簡介
Hadoop 生態系立基於分散式檔案系統 HDFS,可以存放 TB 級,乃至於 PB 級的大資料。
Hive 提供類 SQL 的介面,省去開發分散式運算框架的 JAVA 程式的功夫,方便資料倉儲的施作。可以撰寫腳本配合排程進行 ETL,也能夠搭配 ETL 工具來完成資料倉儲的作業,如Trinity、Informatica 及 Pentaho 等。
然而,Hive 緩慢的查詢速度令許使用者苦惱,Impala 應運而生。
Impala 提供 MPP(大規模平行處理)SQL Engine,讓使用者可以快速地取用儲存於 Hive 裡的資料。Impala 即時且低延遲的回應速度,可以作為互動式查詢的介面,適合用來進行即時資料分析,或者搭配 BI 工具使用。
Hive VS. Impala 架構圖
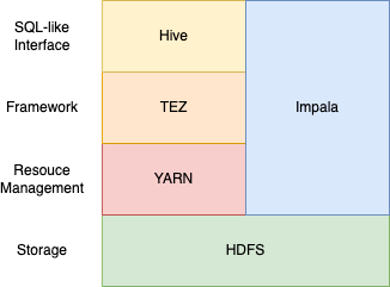
Hive & Impala 比較
架構
資料儲存部分,Hive 與 Impala 的資料都是落地在 HDFS 上,元資料則存放在 Hive Metastore 的外部資料庫中,因此,Hive 與 Impala 可以讀寫同一份資料。
Hive VS. Impala 資料讀寫

運算部分,Hive 依賴分散式運算框架以及 YARN 的資源調度,運算過程中會啟動 Mapper 與 Reducer,複雜的運算會經過多輪的 MapReduce,每一輪的 Reducer 會將階段性的計算結果落地在 HDFS 暫存,提供下一輪的運算使用;Impala 則是以 C++ 撰寫的 MPP SQL Engine,不依賴 MapReduce 與 YARN,以其自身的平行處理邏輯來讀寫資料,運算過程中省去啟動 Mapper 與 Reducer 的步驟,並且大量使用記憶體,減少硬碟 I/O,相對提升運算的效率。
查詢、連線與使用
Hive 與 Impala 均提供類 SQL 的語法對資料進行操作,只要熟悉 SQL 就能快速地上手。
Hive 與 Impala 除了原生的 CLI Shell 以外,也可以透過 JDBC 或 ODBC Driver 進行連線,因此可以串接 ETL 工具,如 Informatica、Pentaho 等,以及 BI 工具,如 Tableau 等。另外,兩者都有 Python 函式庫,分別是 PyHive 與 impyla,可以使用 Python 程式連線來讀寫資料,或者進一步串接到 Pandas,將取得的資料做更深入的分析。
Hive 得益於 MapReduce,運算時容錯度大,部分錯誤如 Mapper 執行失敗,並不會影響整個運算的作業,並且 Hive 可以使用 YARN 做資源調度,Scheduler 可以做到 user 級別的資源管理,一方面限制 user 資源的使用上限,一方面又確保 user 可以使用的最少資源,加上 Hive 提供資料匯出匯入 HDFS 與 Local 的語法,相較於 Impala 更適合批次處理的 ETL 作業;Impala 平行處理邏輯雖然容錯度小,單點運算失敗會導致整個運算失敗,但是查詢速度快,重新查詢成本低,更適合做互動式查詢。
Hive VS. Impala 比較表

使用注意事項
由於 Hive 與 Impala 架構上的不同,但是兩者都能操作同一份資料,因此使用時有一些細節需要注意:
- 讀取表
Hive 內部表預設屬性 CRUD transactional,但是 Impala 無法讀取此類的表,若要確保該表兩者皆能讀取,透過 Hive 建內部表時,需要將表的改為 Insert-only transactional,或者改建外部表。 - 寫入表
Hive 內部表預設的儲存檔案格式為 ORC,但是 Impala 無法寫入此種檔案格式,若要確保該表兩者都能寫入,透過 Hive 建內部表時,需要改以 Parquet 或 Textfile 儲存資料。 - HDFS 檔案權限
由於實際資料落地於 HDFS,Hive 與 Impala 於 HDFS 通常是不同 user,若要確保兩者能夠讀寫同一份資料,需要注意檔案的權限設定。 - 複雜型態資料
Impala 無法直接讀取複雜型態(如ARRAY、MAP、STRUCT)的資料,需要轉型成簡單型態(Scalar Type,即一個欄位一個值)才能讀取,並且不支援 UNION 這個複雜型態。
結語
Impala 的出現並不是要取代 Hive。Hive 負責 ETL 作業做好資料倉儲,Impala 提供即時快速的查詢,也可以將整理過的資料另做資料市集。兩者分工合作在 Hadoop 生態系中相輔相成,完成大數據平台的各種任務。
本文章由歐立威技術顧問撰寫而成,轉載請註明出處,內容若有侵權請來信告知
參考資料
https://stackoverflow.com/questions/38218200/hive-data-to-pandas-data-frame
https://docs.cloudera.com/runtime/7.2.10/using-hiveql/topics/hive_hive_3_tables.html



